Scheduled vs Event-Driven Automation: Cron Jobs That Look Fine Until DST Hits

Naomi Brooks
May 9, 2026

Cron is the comfort food of automation: five fields, a shell command, the illusion of determinism. Then daylight saving time arrives, and your “2:30 a.m. Sunday job” either never fires, fires twice, or fires at a wall-clock instant that collides with another maintenance window you forgot shared the same minute. Event-driven systems are not immune to time weirdness either, but they distribute assumptions differently. The useful framing is not “cron bad, queues good,” but “what happens when civil clocks lie?”
This article walks DST edge cases, why scheduled jobs blow up more visibly than consumers notice, and how to pair schedules with events without turning your platform into a Rube Goldberg machine.
If you only walk away with one habit: store intent in a timezone-aware calendar model, execute work in UTC instants, and log both the civil label and the instant when something fires. Ambiguity loves silent logs.
What DST does to naive schedules
In spring-forward regions, an hour vanishes from local civil time. A cron expression anchored to local time has nothing to map to during the gap; many cron implementations skip or defer ambiguous entries depending on OS and tz database version. In fall-back, an hour repeats; jobs can run twice unless guarded. UTC does not care, but humans and legal business hours insist on local labels—so your choice is not “avoid time zones,” it is “centralize the pain where you can test it.”
Why “store everything in UTC” is necessary but insufficient
UTC storage for timestamps is table stakes. Scheduling “every Monday at 9:00 America/Chicago” still requires a timezone-aware calendar layer that understands DST transitions when translating to instant hits on workers. Libraries exist; wiring them consistently across services is the hard part.
Event-driven mitigation without fanaticism
Queues and log-driven consumers react to work appearing, not to wall clocks—mostly. You still need backpressure, poison pill handling, and deduplication when the same file lands twice because a poller woke up in both ambiguous hours. Idempotency keys save more lives than Kafka branding.
Hybrid patterns that survive politics and power outages
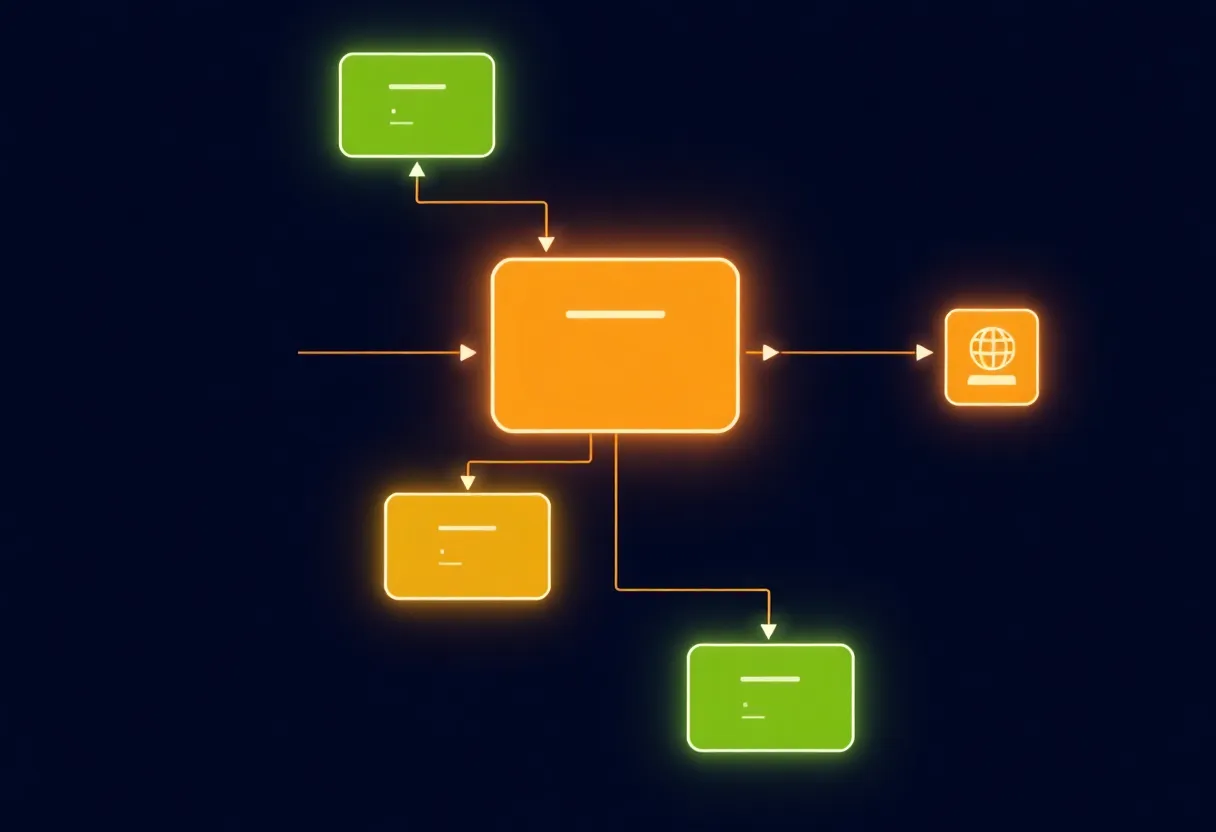
Use cron—or systemd timers, Airflow schedules, Windows Task Scheduler—as a wake-up call that enqueues durable work items. Workers process the queue with retries and metrics. The clock only decides when to peek; the queue decides what ran successfully. Document the split so on-call knows which dashboard to open at 3 a.m.
When power blinks and NTP steps, schedulers may think they missed a window or need to catch up. Idempotent enqueue operations make those corrections boring instead of fiscal. Treat “at least once” delivery as the default truth; “exactly once” remains a negotiation between your broker, your database, and your appetite for math.
Testing calendars like you test parsers
Property-based tests around timezone edges catch off-by-one-hour bugs cheaper than postmortems. Freeze time libraries help. Add fixtures for spring and fall in multiple zones if you serve multinational tenants.
Leap seconds, leap days, and bonus footguns
DST is not the only civil time prank. Leap years break “last day of month” jobs that hardcode 30-day math. Leap seconds mostly moved to smearing strategies on public clouds, but embedded systems still surprise you. Cron’s simplicity hides a dependency on the entire global timekeeping bureaucracy.
Overlapping runs and lock semantics
Long-running jobs started on a cadence need distributed locks or leader election. Otherwise fall-back double triggers overlap workers, duplicate payouts, or double-send customer emails. Postgres advisory locks, Redis Redlock (with known caveats), or orchestrator-level concurrency policies each trade complexity for safety—pick one deliberately.
Observability: lag metrics versus wall-clock alarms
Alert on processing lag and backlog depth, not only “did cron entry execute.” A job that fired but stalled mid-file matters more than systemd claiming happiness. Traces that connect enqueue to completion tell the truth schedules hide.
Serverless schedules and hidden TZ defaults
Cloud vendor cron expressions often default to UTC while console UIs show local. Double-check the actual trigger instant in the API response, not the screenshot. Multi-region deployments multiply surprises when a “daily” job in us-east-1 is not the same calendar day in Sydney.
Business calendars versus solar calendars
Financial close jobs care about market holidays, not only DST. Combine holiday calendars with tz-aware scheduling libraries; never reinvent NYSE closures in YAML unless you enjoy SEC-adjacent regret.
When pure events win
Ingest pipelines that react to object storage notifications or database change streams avoid polling entirely—until the notification channel lags and you add a reconciliation sweep anyway. Purity is rare; pragmatism is common.
When pure schedules still make sense
Periodic compaction, certificate rotation checks, and cost reports align naturally to schedules. Keep them dumb and fast; push heavy lifting to idempotent workers. The schedule is a metronome, not a symphony.
Human factors: on-call and local sleep
Rotating maintenance windows across regions spreads pain. Document who owns DST test updates when politicians change rules—because they still do.
Migrations between orchestrators
Moving from cron to Kubernetes CronJob to managed workflow engines rewrites timing semantics. Regression-test transitions with parallel shadow runs counting outputs, not only “green” health checks.
Documentation template
For each scheduled job, record owner, SLO, max runtime, lock key, timezone, DST notes, and rollback. Future you is bleary; future legal counsel cares about money movement timing.
Jitter, thundering herds, and friendly randomness
Thousands of nodes waking at exactly midnight local to renew certificates creates correlated load spikes. Add jitter within a window so civil midnight does not become distributed denial of self. Schedulers like systemd support randomized delays; Kubernetes CronJobs benefit from spread fields where available.
Backfills after outages
When a region sleeps through an outage window, cron may skip runs entirely. Decide explicitly whether to backfill missed windows or accept gaps. Event-sourced systems replay; naive cron does not—unless you build reconciliation jobs, which are themselves schedules needing answers.
Dead-letter queues and poison schedules
A job that always throws on Tuesday corrupts metrics if it retries forever. Route failures to DLQs with alert thresholds. Sometimes the correct fix is disabling the schedule until data upstream heals—document who can flip that bit.
Airflow, Prefect, Dagster: orchestrated calendars
Workflow engines encode dependencies richer than five-field cron. They still rely on clock triggers at roots—DST bugs migrate into DAG start times instead of disappearing. Sensors waiting on partitions can deadlock if partitions arrive late during DST-shifted batch windows; test sensor timeouts.
Celery beat, Sidekiq-Cron, Quartz, and Windows Task Scheduler
Each stack ships subtly different semantics for misfire, coalescing, and persistence. Upgrading minor versions has changed DST tables underneath apps. Keep integration tests that run in CI on both Linux and Windows if you support both—Task Scheduler’s daylight rules are not Linux cron’s rules.
Database-internal schedulers
Postgres pg_cron, SQL Server Agent jobs, and Oracle DBMS_SCHEDULER tie business logic to database uptime. That localizes failure domains—sometimes helpfully—and couples release cadence to DBA change windows. Know which team owns DST upgrades for the DB host OS versus the DB engine.
Rate limits on downstream APIs
Scheduled pulls that assume “midnight is quiet” ignore SaaS vendors whose peak is another continent’s business hours. Coordinate with vendor rate cards; exponential backoff belongs in scheduled tasks too.
Security: cron injection and writable crontabs
World-writable cron directories or unvalidated environment variables become privilege escalation paths. Treat schedule definitions like code: review, version, scan.
Cost optimization versus reliability
Spot instances under scheduled workers save money until preemption aligns with your heaviest job. Mixed fleets or checkpointing reduce pain; pure optimism reduces sleep.
Choosing between cron-first and event-first for a new service
Ask whether work is inherently periodic or inherently reactive. Reporting is periodic; user uploads are reactive. Hybrids enqueue on both; document precedence when both fire. Conflicts become merge strategies, not mysteries.
Closing habit
Whenever you add a schedule, answer three questions: Which zone? What happens on DST? What if the job overlaps itself? If the doc is blank, the pager will fill it in later.
Runbooks for the two scary nights each year
Put spring and fall DST on the engineering calendar with a lightweight checklist: verify billing jobs, certificate renewals, analytics rollups, and anything touching bank cutoffs. Run a canary job that logs the resolved instant before and after the transition. Screenshots of dashboards beat oral tradition when finance asks why March looked weird.
Customer-facing promises
If marketing promises “reports at 8 a.m. local,” engineering must encode what “local” means for multi-site retailers. Failure modes include reports arriving during store opening rush or before night reconciliation closes. Align language with implementation or align lawyers with language.
Observability sampling during high-churn nights
Temporarily lower sampling suppression on scheduler spans around DST windows the first year after a migration. The noise buys confidence; you can tighten later.
Civil time is a social contract; computers execute instants. Cron lives on the border. Respect the border, test the border, then—if you must—tweet about the border with screenshots so the rest of us can avoid your outage.




